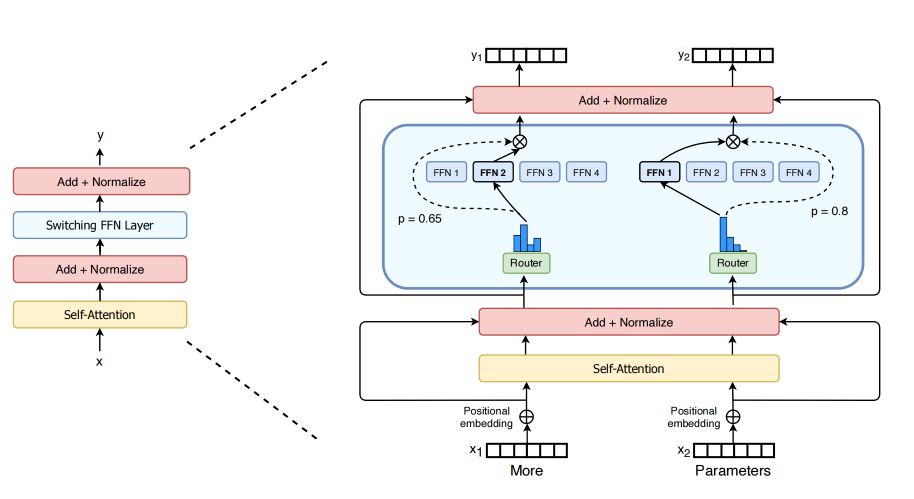
Switch Transformer Contents MoE: Mixture of Experts MoE: Mixture of Experts sparsely-activated model: 为每个传入的样本选择不同的参数。拥有庞大的参数,然而计算代价不变。 Switch Transformer: 简化MoE路由算法,减少通讯和计算开销。 Share on: Twitter ❄ Facebook ❄ Email Comments Comments Related Posts Nucleus Sampling Top-p Sampling Universal Chart Structural Multimodal Generation and Extraction MinHash: Document-level Deduplication GGUF Model LLM Agent Published Jan 21, 2025 Category LLM Tags LLM 9 MoE 1 Contact